API In Action
The screenshots below show a thin demo frontend wrapping the API. The frontend masks sensitive output for public viewing — the actual API returns complete data. Click any image to enlarge.
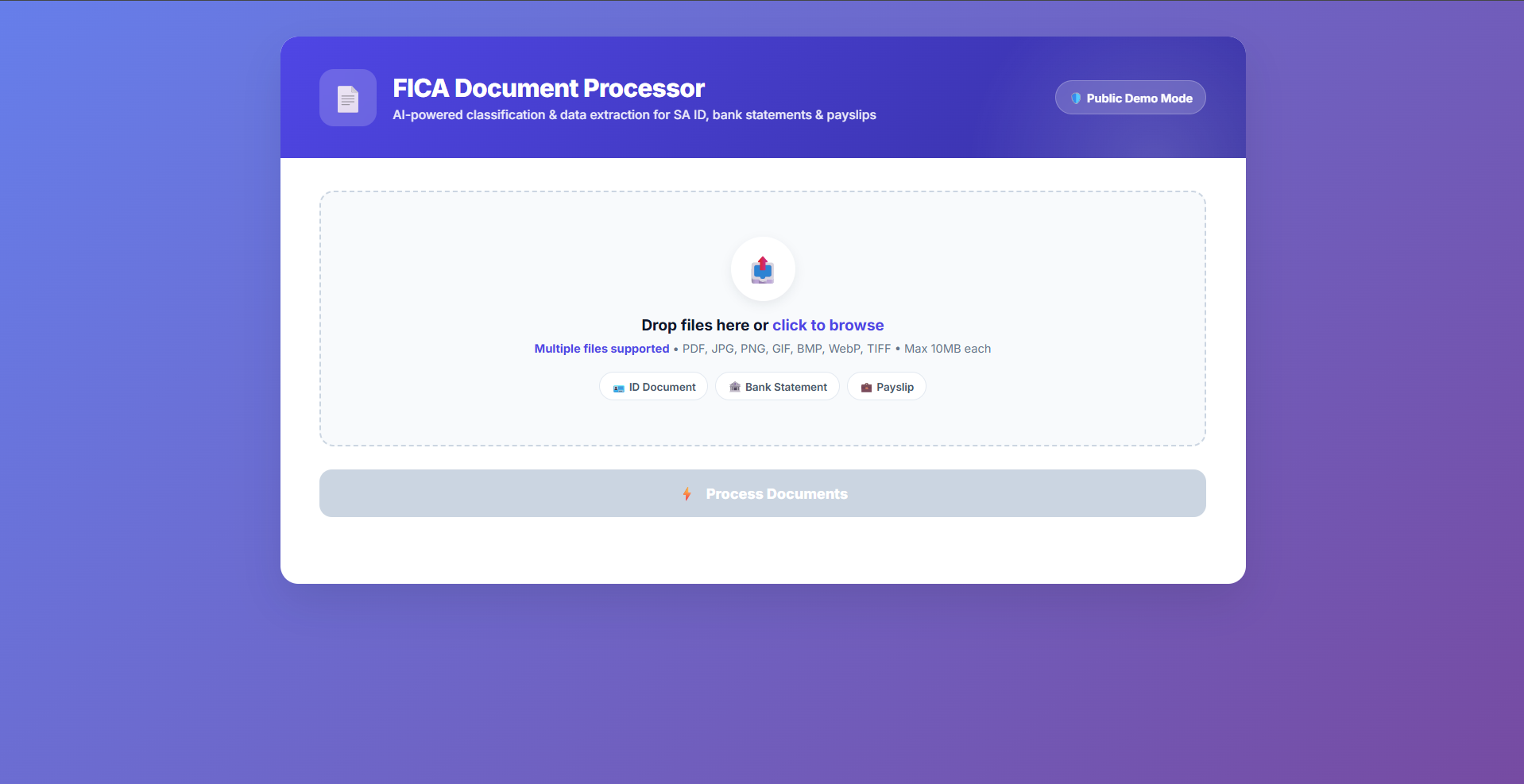
Document Upload
Drag-and-drop or browse to queue multiple files for the API. Supports PDF and common image formats.
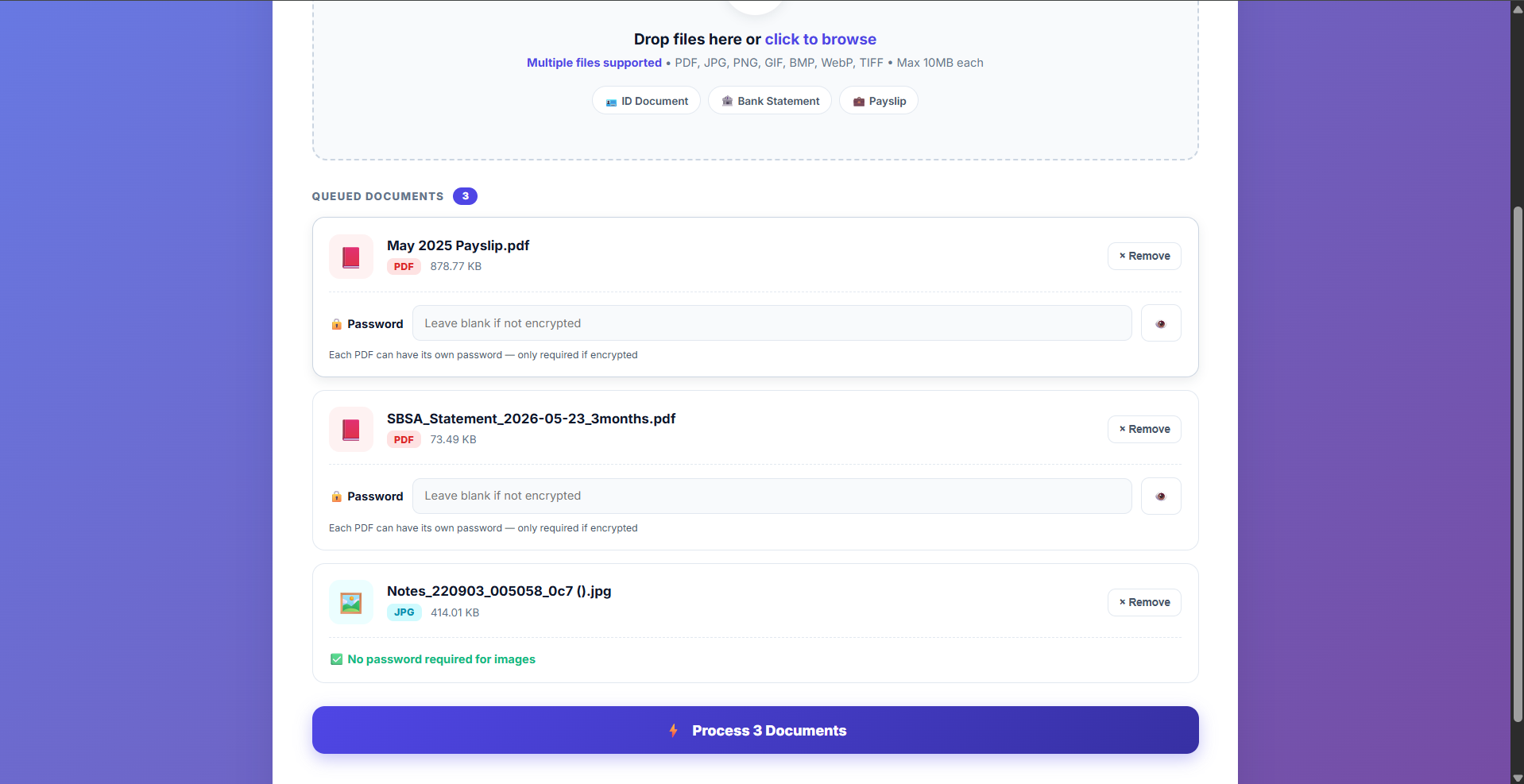
Per-File Passwords
Encrypted PDFs (like password-protected payslips) can be unlocked individually before processing.
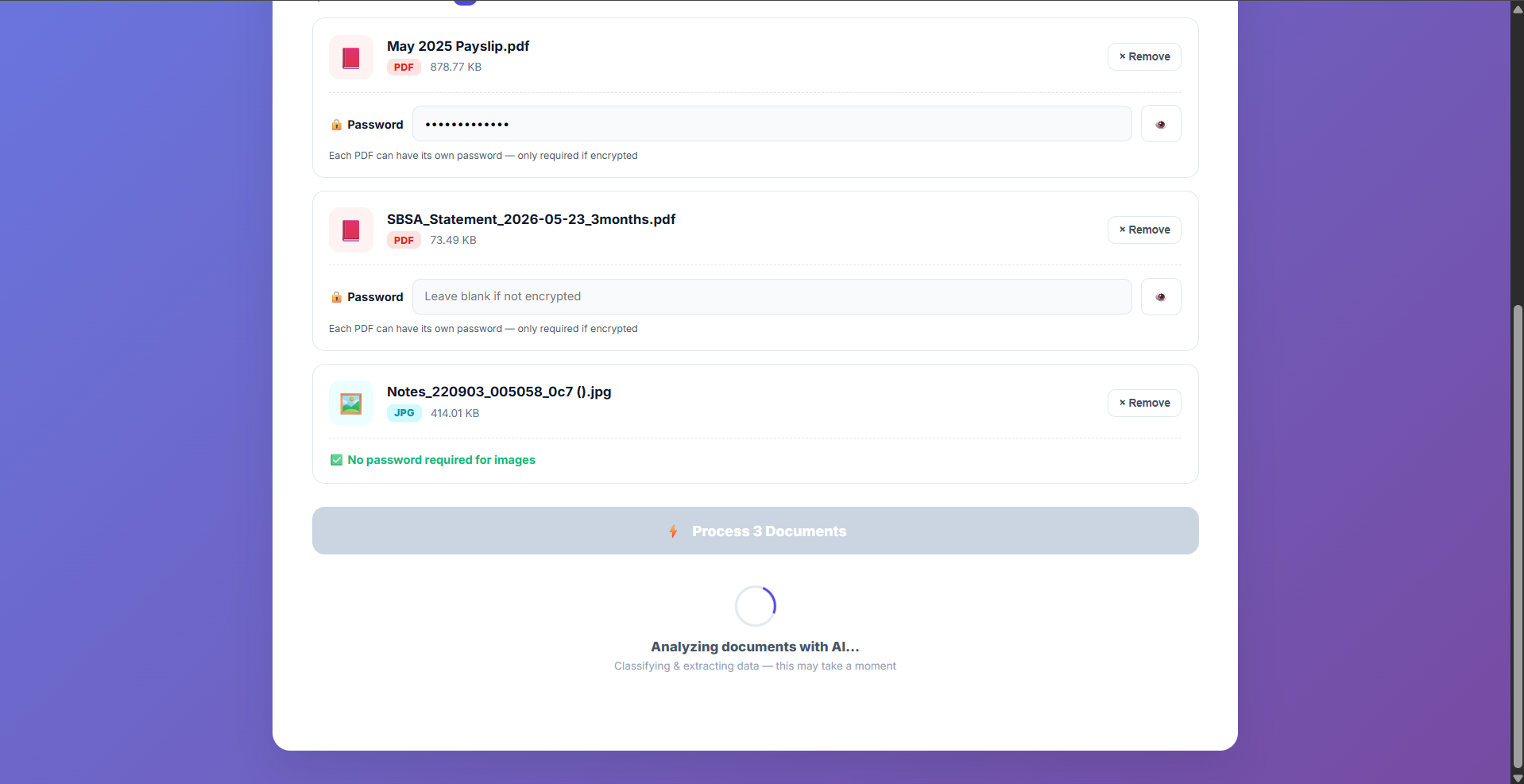
AI Analysis
Documents are classified and parsed using OpenAI — each file is handled with type-specific logic.
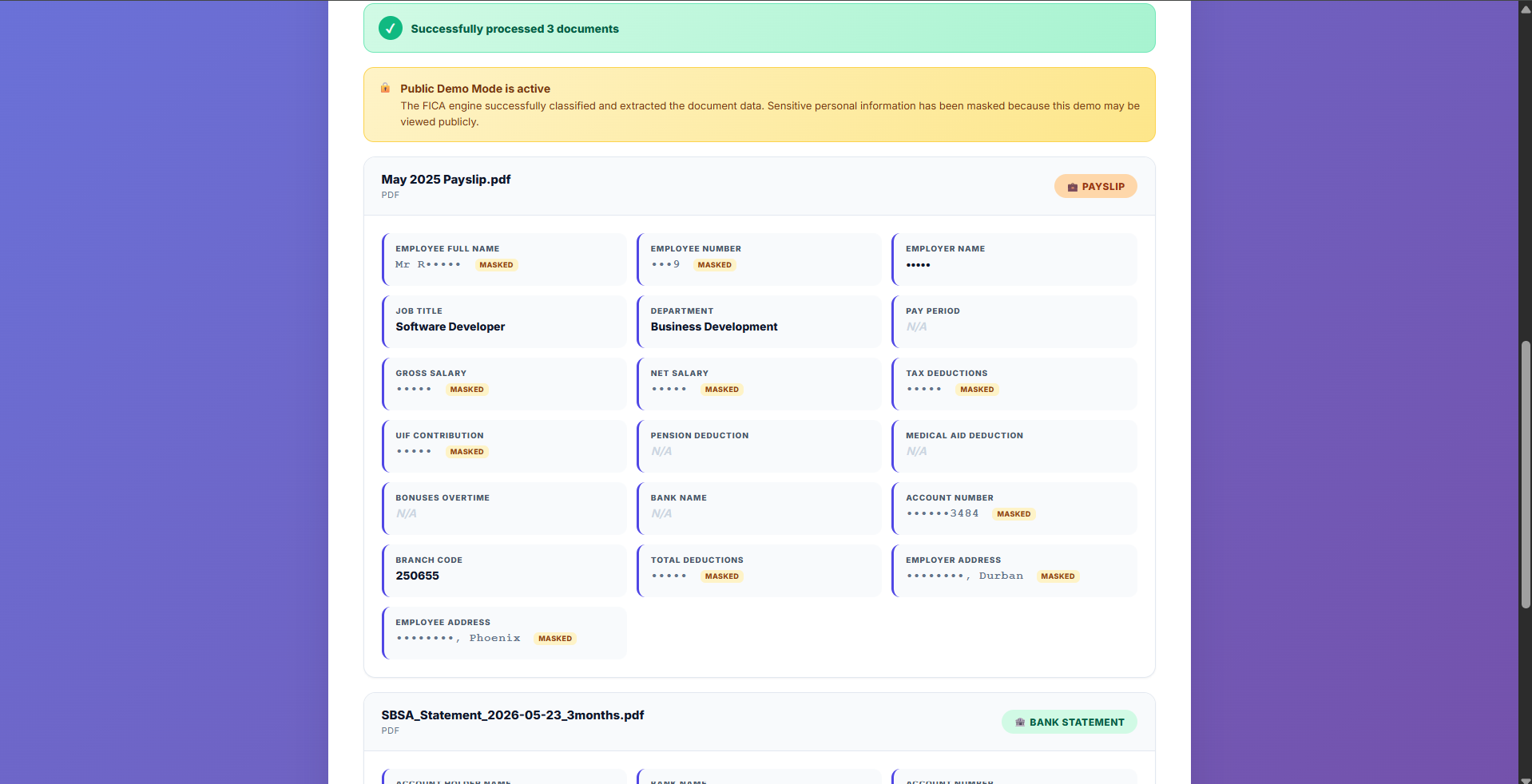
Payslip Extraction
Employer, employee, salary breakdown, deductions, and banking details — all extracted automatically.
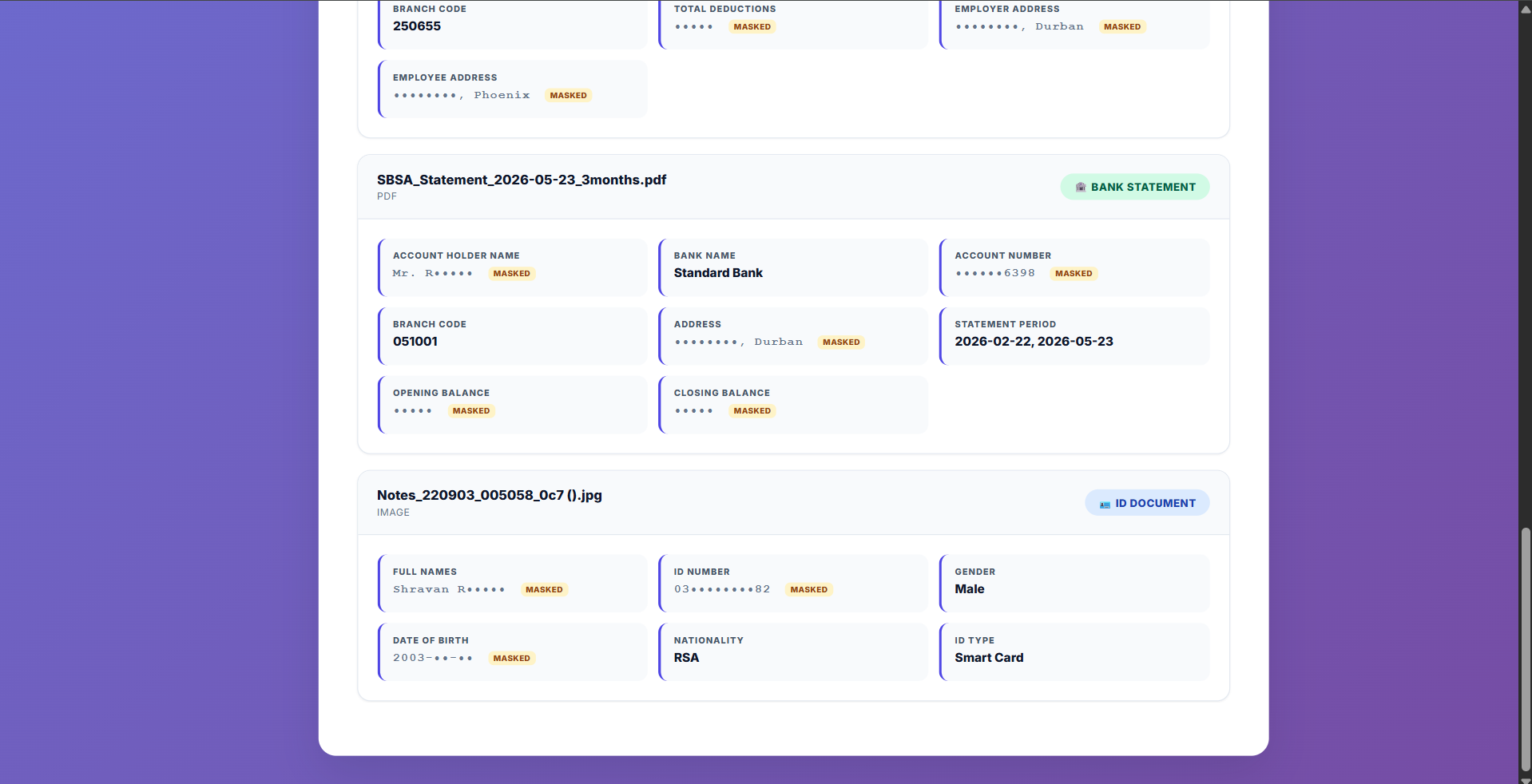
Bank Statement & ID Extraction
Bank statement metadata and full ID document fields returned in a single batch response.